优化一个博客网站(三):按标签分类。
scope/work/site roadmap/blog_site
按标签分类
改点东西
之前加过一个 markdown-it-hashtag 的插件, 不过它默认把所有的 # 和标签文本放在一起, 这样一来,除了使用 JS, 没有比较好的方式来隐藏这个 #。
看看 markdown-it-hashtag 的 repo,里面讲了怎么去配置标签的文本以及生成的 HTML tag 的结构。
还有一个问题是,它默认的 regex 是 \\w+, 这意味着它只能处理一个层级的标签。
所以进行了下面的配置:
import { defineConfig } from 'vitepress'
// ...
export default defineConfig({
// ...
markdown: {
config: (md) => {
md
.use(markdownItHashtag, {
hashtagRegExp: '\\w+(\\/\\w+)*',
})
// ...
md.renderer.rules.hashtag_text = function (tokens, idx) {
return `${tokens[idx].content}`
}
md.renderer.rules.hashtag_open = function (tokens, idx) {
const tagName = tokens[idx].content.toLowerCase()
return `<a href="/tags/${tagName}"><span class="tag">`
}
md.renderer.rules.hashtag_close = function () {
return `</span></a>`
}
}
}
})好了,现在点击一个标签,比如 #blog/test, 就会跳转到 /tags/blog/test。
然后你就会发现你其实去了 404。
标签页面
所以,现在我们需要一个标签页面, 来显示这个标签下的所有文章。 这里我们用到 VitePress 的 动态路由 来实现。
首先,在 docs/ 目录下新建一个 tags 文件夹, 然后在里面新建一个 [tag].md 和 [tag].paths.ts 文件。 我们将在这个 [tag].paths.ts 文件中配置所有 /tags/[tag] 的路由, 其中 [tag] 就是动态路由的参数,我们可以用它来筛选文章。
这里会出现一些问题。 首先,我们当然需要在这个文件中写入所有存在的标签, 我第一时间想到的是用 posts.data.ts 文件中的数据来做, 因为它正好在对文章进行处理, 应该可以比较方便地获得所有标签, 否则还需要再对所有 markdown 文件进行一次处理。
但是问题在于,[tag].paths.ts 是在构建时执行的。 事实上,在经过尝试之后, 我发现它甚至是在 VitePress 开始构建之前——或者说是独立于 VitePress 进程—— 执行的。 官网文档 中也提到了,路径加载器是在 Node.js 环境中运行的。 这导致了无法在 [tag].paths.ts 中获取到 posts.data.ts 中导出的数据, 因为后者是一个「正宗」的构建时导出。
所以这里如果不想用 hacky 的枚举法, 可能就需要用一些 Node.js 的方法来处理文件了, 比如 fs 之后正则。 不过我还没有找到一个很优雅的方法去避免正则匹配到代码块中的 #123, 所以这里还是先用枚举法了。
现在再点开刚刚的链接, 一片黑,但至少不是 404。
获取文章的标签
不过实际上,post.data.ts 中也需要提取标签, 因为要根据标签对文章进行筛选。 用正则来做:
import { createContentLoader } from 'vitepress'
// ..
export interface Data {
// ..
tagsExtended: string[]
tags: string[]
}
// ...
function dealTagHierarchy(tag: string): Set<string> {
const tags = new Set<string>()
const levels = tag.split('/')
levels.forEach((_: string, i: number) => {
tags.add(levels.slice(0, i + 1).join('/'))
})
return tags
}
function getTags(
html: string | undefined,
frontmatter: Record<string, any>,
): {
tags: Set<string>
tagsExtended: Set<string>
} {
let tagsExtended: Set<string> = new Set()
const tags: Set<string> = new Set()
if (!html) {
return {
tags,
tagsExtended,
}
}
const tagReg = /<a href="\/tags\/[^"]*">\s*<span class="tag">(.*?)<\/span>\s*<\/a>/g
let match: RegExpExecArray | null = tagReg.exec(html)
while (match) {
tags.add(match[1])
tagsExtended = new Set([...tagsExtended, ...dealTagHierarchy(match[1])])
match = tagReg.exec(html)
}
if (frontmatter.tags) {
frontmatter.tags.forEach((tag: string) => {
tags.add(tag)
tagsExtended = new Set([...tagsExtended, ...dealTagHierarchy(tag)])
})
}
return {
tags,
tagsExtended,
}
}
export default createContentLoader('posts/**/*.md', {
// ...
transform(raw) {
return raw.map(({ html, url, frontmatter, excerpt, src }) => ({
// ...
tags: [...getTags(html, frontmatter).tags],
tagsExtended: [...getTags(html, frontmatter).tagsExtended],
}))
.sort((a, b) => b.created.raw.getTime() - a.created.raw.getTime())
},
})首先,这里用 html 去提取,就可以很好地避免刚刚说的问题, 就是其实不够美丽。
其次,我们需要考虑标签的层级, 即对于 #a/b/c 这样的标签,需要提取出 #a, #a/b, #a/b/c 这三个标签。 所以在这里, 我们定义了 dealTagHierarchy() 函数来处理标签的层级。
最后,我们可能会在文章的 frontmatter 中定义标签, 这里用了相同的逻辑处理,然后加入到 tags 中。
页面渲染
一片黑很好理解, 毕竟我们的 [tag].md 文件是空的。 但看到控制台有报错,是由 PageContentPost.vue 抛出的。 懂得人已经懂了,我们在 PageContent.vue 中的 DOM 是这样的:
<script setup lang="ts">
import { useData, useRoute } from 'vitepress'
import PageContentHome from './PageContentHome.vue'
import PageContentNotFound from './PageContentNotFound.vue'
import PageContentPost from './PageContentPost.vue'
const { page, frontmatter } = useData()
</script>
<template>
<PageContentHome v-if="frontmatter.home" />
<PageContentNotFound v-else-if="page.isNotFound" />
<PageContentPost
v-else
:key="page.filePath"
/>
</template>也就是说,只要不是主页, 我们就会去渲染 PageContentPost.vue。 我们可以在 PageContentPost.vue 中添加额外的逻辑去渲染标签的页面, 但当然我们也可以新开一个组件, 毕竟你都叫 ...Post 了,那我还说啥呢兄弟?
新做一个 PageContentTags.vue,然后在 PageContent.vue 中条件渲染。
<script setup lang="ts">
import { useData, useRoute } from 'vitepress'
import PageContentHome from './PageContentHome.vue'
import PageContentNotFound from './PageContentNotFound.vue'
import PageContentPost from './PageContentPost.vue'
import PageContentTag from './PageContentTag.vue'
const { page, frontmatter } = useData()
const { path } = useRoute()
</script>
<template>
<PageContentHome v-if="frontmatter.home" />
<PageContentNotFound v-else-if="page.isNotFound" />
<PageContentTag
v-else-if="frontmatter.tag"
/>
<PageContentPost
v-else
/>
</template>简单先写一下 PageContentTag.vue:
<script setup lang="ts">
import { useData } from 'vitepress'
const { params } = useData()
</script>
<template>
<div>
{{ params!.tag }}
</div>
</template>现在再点进去看看呢:

看到了当前动态路由的 tag 参数了。那现在就可以根据这个参数来筛选文章了。
文章筛选
也就是说现在来做一下 PageContentTag.vue 中的逻辑。
直接看效果:
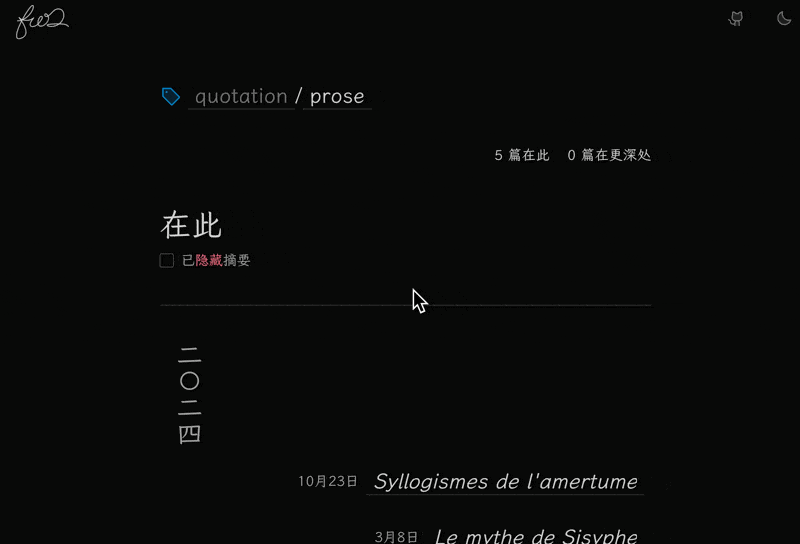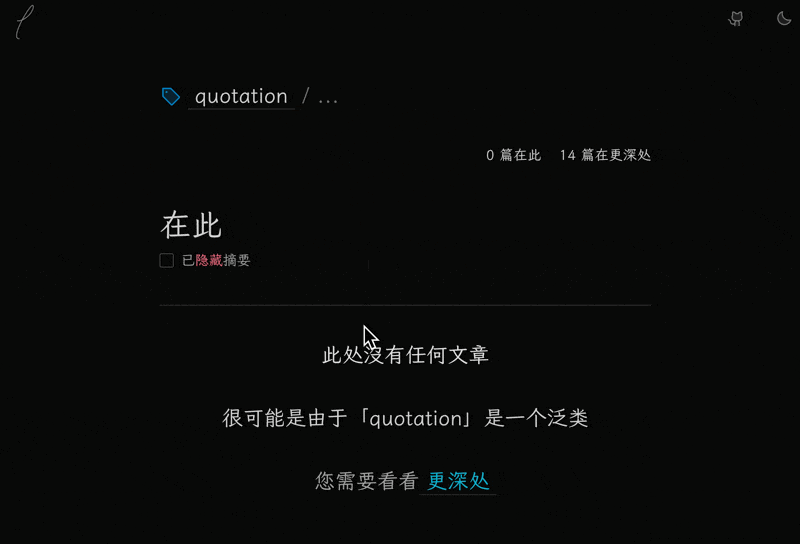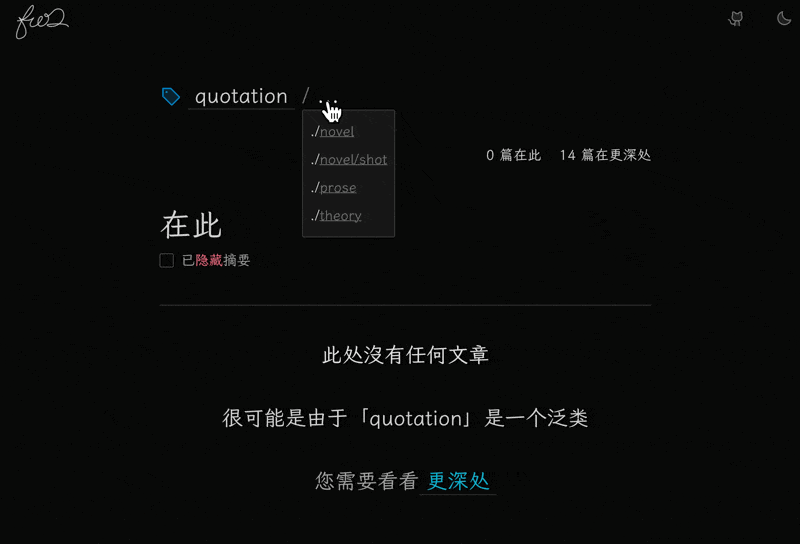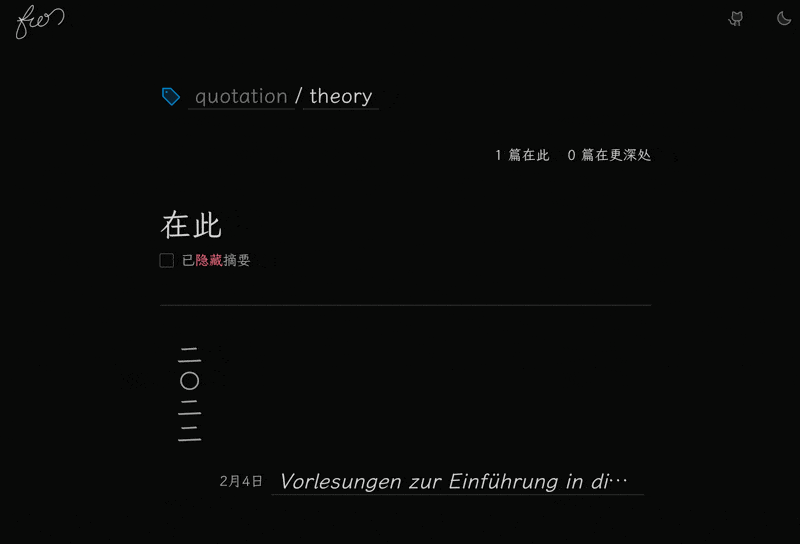
这里我重构了很多文件,所以就先不放代码了。 简单说一下。
首先是最上面, 做了一个层级式的标签展示,点击上层就可以去。 如果当前标签有下层标签,则点一下那三个点就可以展开一个下层标签列表。
然后是下面的文章列表。 展示了两部分的文章:在此处的和更深处的。
这里的具体逻辑就不展开讲了。 如果有问题可以问我。